사내 문서 Rag 검색 챗봇 프로토타입 완성!
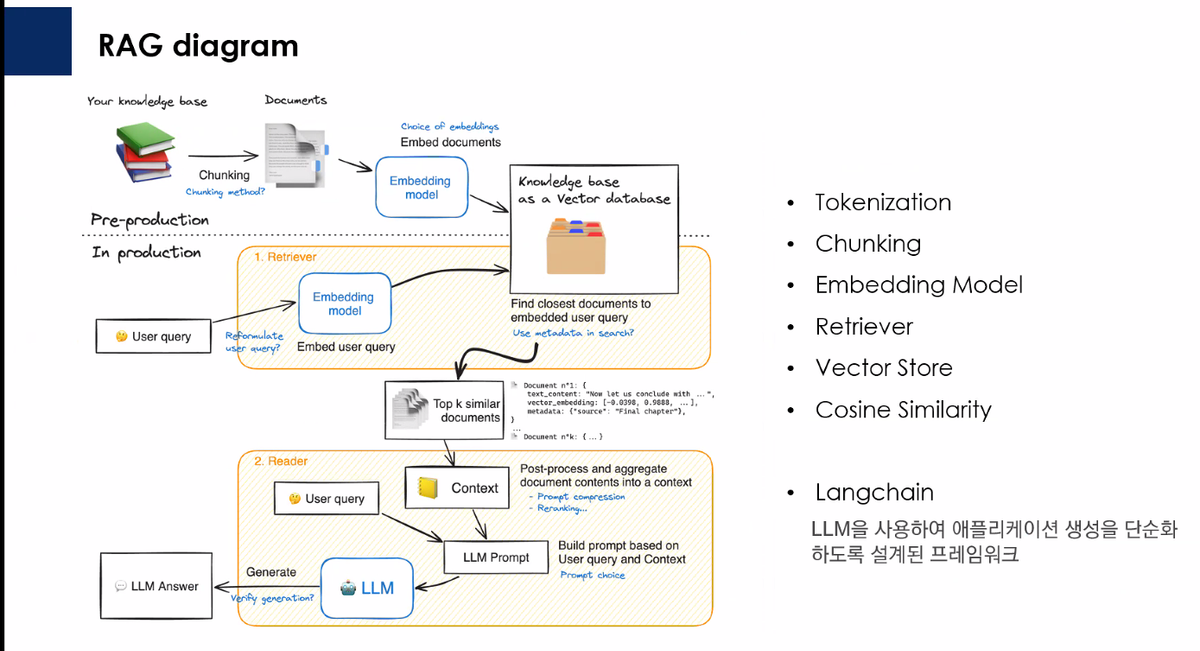

최근에 회사에서 AI 프로젝트 진행하다가 임베딩 관련된 부분을 다른 분과 협업했는데 공부 겸 사내 문서들로 RAG 챗봇 프로토타입을 만들었습니다.
Redmine이라는 툴로 사내에 기술, 이슈 등 수많은 문서를 활용해서 자연어로 질문하면 답변해주는 챗봇을 만들었습니다.
쌓인 문서는 많지만 제 계정으로 접근할 수 있는 문서는 저와 관련된 프로젝트만 있습니다. 보안 상 데이터는 모두 회사 내의 네트워크에만 존재합니다.
왜 만들었나요?
회사에서 Redmine을 사용하다 보니, 과거에 해결했던 이슈나 비슷한 문제를 찾기 위해 검색을 자주 하게 됨. 그런데 키워드 검색만으로는 원하는 정보를 찾기 어려운 경우가 많음. "이전에 비슷한 버그를 어떻게 해결했더라?" 같은 질문에 자연스럽게 답변해주는 시스템이 있으면 좋겠다고 생각했고 저와 같은 생각을 가진 팀원들도 있었습니다.
그래서 RAG 기술을 활용해서 벡터 검색과 LLM을 결합한 챗봇을 만들어봤습니다. 이제 "최근 3개월 내 버그 관련 문서" 같은 자연어 질문으로 원하는 정보를 찾을 수 있습니다
1. 전체 아키텍처
전체 시스템은 크게 백엔드 API 서버와 크롬 확장 프로그램, 관리자 UI 로 구성되어 있어요. 오늘은 전반적인 구조와 RAG, 백엔드 아키텍처에 대해 설명하는 포스팅이 될 것 같네요.
기술 스택
- 프론트엔드: React, Tailwind, Shadcn, Tanstack, zod
- 백엔드: NestJS, Typeorm, zod
- 데이터베이스: PostgreSQL + pgvector (벡터 검색용)
- LLM & 임베딩: Google Gemini API (LLM, Embeding Model)
- 문서 변환: Pandoc (Textile → HTML → Markdown)
- 아키텍처 패턴: DDD (Domain-Driven Design)
시스템 구조
┌──────────────────────┐ ┌──────────────────────┐
│ 크롬 확장 프로그램 | │ 프론트엔드 │
│ (챗봇 위젯) │ │ (관리자 페이지) │
└──────────┬───────────┘ └──────────┬───────────┘
│ │
│ HTTP │ HTTP
│ (RAG Query) │ (Admin APIs)
│ │
└────────────┬───────────────────┘
│
▼
┌───────────────────────────────────┐
│ Backend API (NestJS) │
├───────────────────────────────────┤
│ Presentation Layer │
│ ├─ RAG Query Controller │
│ ├─ Redmine Sync Controller │
│ ├─ Chunking Controller │
│ └─ Settings Controller │
│ ↓ │
│ Application Layer │
│ ↓ │
│ Domain Layer │
│ ↓ │
│ Infrastructure Layer │
└───┬───────────────────────────────┘
│
├─→ Redmine API
├─→ Gemini API
├─→ Pandoc Service
└─→ PostgreSQL (pgvector)
DDD 레이어 구조
NestJS를 사용하면서도 DDD 원칙을 적용해서 각 모듈을 4개 레이어로 나눴습니다:
- Presentation Layer: HTTP 요청/응답 처리 (Controller, DTO)
- Application Layer: 비즈니스 로직 조율 (Use Cases)
- Domain Layer: 핵심 비즈니스 규칙 (Entities, Domain Service, Repository Interfaces)
- Infrastructure Layer: 외부 서비스 연동 (Repository 구현, 외부 API 클라이언트)
이렇게 하면 도메인 로직과 인프라스트럭처를 분리해서 테스트하기도 쉽고, 나중에 다른 벡터 DB나 LLM으로 교체하기도 편해요.
2. 데이터 파이프라인
RAG 챗봇이 제대로 작동하려면 먼저 문서들을 벡터로 변환해서 저장해야 해요. 전체 파이프라인은 다음과 같아요:
Redmine API → Redmine Sync → Pandoc 변환 → Chunking → Embedding → PostgreSQL
(저장) (Textile → MD) (청킹) (벡터화) (pgvector)
파이프라인 실행 방식
파이프라인은 수동 오케스트레이션 방식으로 구현했어요. 각 단계를 독립적인 API 엔드포인트로 제공해서, 관리자가 필요할 때 단계별로 실행할 수 있게 했습니다. 이렇게 한 이유는:
- 유연성: 특정 단계만 다시 실행하거나, 특정 프로젝트만 처리할 수 있음
- 투명성: 각 단계의 진행 상황을 실시간으로 모니터링 가능
- 안정성: 한 단계가 실패해도 다른 단계에 영향 없음
각 단계는 HTTP POST 요청으로 시작되며, 비동기로 실행됩니다:
// 1. Redmine 동기화
POST /redmine/issues/sync-all
// 2. Pandoc 변환
POST /pandoc/convert-all?project_id=123
// 3. 청킹
POST /chunking/chunk-all?project_id=123
// 4. 임베딩
POST /embedding/embed-all?project_id=123
상태 관리 및 진행 상황 추적
각 단계의 진행 상황은 SyncStatus 엔티티로 추적해요:
// SyncStatus 엔티티
{
operationType: OperationType, // REDMINE_SYNC, PANDOC_CONVERSION, CHUNKING, EMBEDDING
status: SyncStatusType, // IDLE, RUNNING, COMPLETED, FAILED
totalCount: number, // 전체 처리할 항목 수
processedCount: number, // 현재까지 처리한 항목 수
progress: number, // 진행률 (0-100)
startedAt: Date,
completedAt: Date,
errorMessage: string | null
}
각 UseCase는 시작할 때 상태를 RUNNING으로 설정하고, 진행하면서 processedCount를 업데이트해요:
// UseCase 시작 시
await this.syncStatusService.startChunking(totalCount);
// 진행 중
await this.syncStatusService.updateChunkingProgress(processedChunkCount);
// 완료 시
await this.syncStatusService.completeChunking(processedChunkCount);
// 실패 시
await this.syncStatusService.failChunking(errorMessage, processedChunkCount);
프론트엔드에서는 2초마다 상태를 폴링해서 실시간으로 진행 상황을 보여줘요.
1단계: Redmine 동기화
Redmine API를 통해 이슈와 저널을 가져와서 ProcessedIssue와 ProcessedJournal 엔티티로 저장해요. 이슈의 설명(description)과 저널의 노트(notes)가 주요 텍스트 데이터가 되요.
Redmine API에서 이슈를 가져와서 저장하는 과정은 다음과 같아요:
// Redmine API에서 이슈 조회 후 ProcessedIssue로 저장
const redmineIssue = await redmineApiClient.getIssue(issueId);
const processedIssue = new ProcessedIssue();
processedIssue.redmineIssueId = redmineIssue.id;
processedIssue.descriptionRaw = redmineIssue.description; // 원본 Textile 형식
processedIssue.subject = redmineIssue.subject;
processedIssue.issueMetadata = {
trackerName: redmineIssue.tracker?.name,
statusName: redmineIssue.status?.name,
priorityName: redmineIssue.priority?.name,
// ... 기타 메타데이터
};
await processedIssueRepository.save(processedIssue);
2단계: Textile → Markdown 변환
Redmine은 기본적으로 Textile 형식을 사용하는데, 이걸 그대로 사용하기보다는 Markdown으로 변환하는 게 나중에 처리하기 편해요. 또한 Textile에서 안정적으로 markdown으로 변환하기 위해 HTML로 변환 후 markdown으로 변환해요. 이 과정은 Pandoc을 사용해서 변환 작업을 수행해요.
Pandoc 워커 풀을 사용해서 병렬로 변환 작업을 처리해요:
// PandocPreprocessorService
async convertTextileToMarkdown(
textile: string | null | undefined,
): Promise<string | null> {
if (!textile || textile.trim() === '') {
return null;
}
// Textile → HTML → Markdown (2단계 변환)
const html = await this.workerPool.convertTextileToHtml(textile);
if (!html) {
return null;
}
const markdown = await this.workerPool.convertHtmlToMarkdown(html);
return markdown;
}
// UseCase에서 사용
const markdown = await this.documentPreprocessor.convertTextileToMarkdown(
issue.descriptionRaw,
);
if (markdown) {
await this.issueRepository.update(issue.id, {
description: markdown, // 변환된 Markdown 저장
});
}
3단계: 문서 청킹
긴 문서를 그대로 임베딩하면 의미가 희석될 수 있어서, 문서를 작은 청크로 나눠요. 우리는 헤더 기준으로 섹션을 나누고, 각 섹션이 너무 길면 문단 단위로 다시 나누는 전략을 사용했어요.
- 최대 청크 크기: 1000자
- 청크 오버랩: 200자 (문맥 유지를 위해)
청킹 로직은 다음과 같아요:
// DocumentChunkerService
chunkMarkdown(markdown: string): Chunk[] {
// 1. 헤더 기준으로 섹션 분할
const sections = this.splitByHeaders(markdown);
const chunks: Chunk[] = [];
for (const section of sections) {
// 2. 섹션이 너무 길면 문단 단위로 다시 분할
const sectionChunks = this.chunkSection(section);
chunks.push(...sectionChunks);
}
return chunks;
}
private splitByHeaders(markdown: string) {
const lines = markdown.split('\n');
let currentSection: string[] = [];
let currentHeader: { level: number; text: string } | null = null;
for (const line of lines) {
const headerMatch = line.match(/^(#{1,6})\s+(.+)$/);
if (headerMatch) {
// 헤더를 만나면 이전 섹션 저장하고 새 섹션 시작
if (currentSection.length > 0) {
sections.push({
content: currentSection.join('\n'),
headerLevel: currentHeader?.level,
headerText: currentHeader?.text,
});
}
currentSection = [line];
currentHeader = {
level: headerMatch[1].length,
text: headerMatch[2].trim(),
};
} else {
currentSection.push(line);
}
}
// ...
}
// UseCase에서 청크 저장
const chunks = this.chunkerService.chunkMarkdown(issue.description || '');
const chunkEntities: DocumentChunk[] = chunks.map((chunk, index) => {
const entity = new DocumentChunk();
entity.sourceType = ChunkSourceType.ISSUE_DESCRIPTION;
entity.sourceId = issue.id;
entity.chunkIndex = index;
entity.content = chunk.content;
entity.metadata = chunk.metadata; // 헤더 정보 포함
return entity;
});
await this.chunkRepository.saveMany(chunkEntities);
4단계: 벡터 임베딩
각 청크를 Gemini의 text-embedding-004 모델로 벡터화해서 PostgreSQL의 pgvector 확장을 사용해 저장해요. 이렇게 하면 나중에 유사도 검색이 가능해집니다.
임베딩 생성 및 저장 과정:
// GeminiEmbeddingService
async embedText(text: string): Promise<number[]> {
const requestBody = {
model: 'models/text-embedding-004',
content: {
parts: [{ text }],
},
};
const response = await firstValueFrom(
this.httpService.post<GeminiEmbedContentResponse>(
`${this.baseUrl}?key=${this.apiKey}`,
requestBody,
),
);
// 768차원 벡터 반환
return response.data.embedding.values;
}
// UseCase에서 사용
for (const chunk of chunks) {
// 1. 청크 텍스트를 벡터로 변환
const embedding = await this.geminiEmbeddingService.embedText(
chunk.content
);
// 2. DocumentChunk의 embedding 필드에 pgvector 타입으로 저장
await this.embeddingRepository.updateChunkEmbedding(
chunk.id,
embedding, // [0.123, -0.456, ...] 768차원 배열
);
}
PostgreSQL에서 pgvector 타입으로 저장되면, 나중에 코사인 유사도 검색이 가능해져요!
배치 처리 및 성능 최적화
각 단계는 배치 단위로 처리해서 성능을 최적화했어요:
1. Redmine 동기화
- Redmine API에서 이슈를 배치로 가져와서 한 번에 저장
- 이미 동기화된 이슈는
redmineUpdatedOn필드를 비교해서 업데이트 여부 판단
2. Pandoc 변환
- 워커 풀을 사용해서 여러 문서를 병렬로 변환
- 각 문서마다 10분 타임아웃 설정 (긴 문서 처리)
- 연속 실패 10회 시 경고 로그 출력하지만 계속 진행
// Pandoc 워커 풀 설정
const maxWorkers =
configService.get('PANDOC_MAX_WORKERS', { infer: true }) || 1;
const timeout = configService.get('PANDOC_TIMEOUT', { infer: true })!;
// 병렬 처리
const html = await this.workerPool.convertTextileToHtml(textile);
const markdown = await this.workerPool.convertHtmlToMarkdown(html);
3. 청킹
- 배치 크기: 100개 이슈/저널씩 처리
- 이미 청킹된 문서는 건너뛰기 (SQL로 필터링)
// 이미 청킹된 문서 제외
.andWhere(
`issue.id NOT IN (
SELECT chunk.source_id
FROM document_chunks chunk
WHERE chunk.source_type = :issueSourceType
)`,
{ issueSourceType: ChunkSourceType.ISSUE_DESCRIPTION }
)
4. 임베딩
- 배치 크기: 100개 청크씩 처리
- Gemini API 호출은 순차적으로 (Rate Limit 방지)
- 진행 상황을 실시간으로 업데이트
const batchSize = 100;
let offset = 0;
while (true) {
const chunks = await this.embeddingRepository.findChunksWithoutEmbedding(
batchSize,
offset,
projectIds,
);
if (chunks.length === 0) break;
for (const chunk of chunks) {
const embedding = await this.geminiEmbeddingService.embedText(
chunk.content,
);
await this.embeddingRepository.updateChunkEmbedding(chunk.id, embedding);
processedCount++;
// 진행 상황 업데이트
await this.syncStatusService.updateEmbeddingProgress(processedCount);
}
offset += batchSize;
}
중복 방지 및 재실행 안전성
각 단계는 멱등성(idempotent) 을 보장해요:
- Redmine 동기화:
redmineIssueId로 중복 체크, 업데이트된 경우만 재처리 - Pandoc 변환:
descriptionRaw가 있고description이 없는 경우만 변환 - 청킹: 이미 청크가 존재하는 문서는 건너뛰기
- 임베딩:
embedding필드가 NULL인 청크만 처리
이렇게 하면 중간에 실패해도 다시 실행하면 실패한 부분만 처리해서 안전하게 재시작할 수 있어요.
프로젝트별 처리
특정 프로젝트만 처리하고 싶을 때는 project_id 파라미터를 전달하면 돼요:
// 특정 프로젝트와 하위 프로젝트만 처리
if (projectId) {
const project =
await this.projectRepository.findOneByRedmineProjectId(projectId);
const descendants = await this.projectRepository.findDescendants(project);
projectIds = [project.id, ...descendants.map((d) => d.id)];
}
Redmine의 프로젝트 계층 구조를 유지해서, 상위 프로젝트를 지정하면 하위 프로젝트까지 자동으로 포함돼요.
에러 핸들링 전략
각 단계마다 다른 에러 핸들링 전략을 사용해요:
- Pandoc 변환: 개별 문서 변환 실패해도 계속 진행 (연속 실패 10회 시 경고)
- 청킹: 개별 문서 청킹 실패 시 에러 로그만 남기고 계속 진행
- 임베딩: 개별 청크 임베딩 실패 시 전체 작업 중단 (데이터 무결성 보장)
이렇게 하면 일부 문서에 문제가 있어도 전체 파이프라인이 멈추지 않아요.
3. 주요 모듈별 기능
Redmine 모듈
Redmine API와 통신해서 이슈와 저널을 동기화하는 모듈이에요. 주요 기능은:
- 이슈/저널 동기화: Redmine에서 최신 데이터를 가져와서 DB에 저장
- 프로젝트 계층 구조 관리: Redmine의 프로젝트 계층 구조를 유지
- 동기화 상태 관리: 동기화 진행 상황을 추적하고 관리
동기화는 배치로 처리되며, 이미 처리된 이슈는 업데이트된 경우에만 다시 처리해요.
Pandoc 모듈
Textile 형식의 문서를 Markdown으로 변환하는 모듈입니다. Pandoc을 워커 풀로 관리해서 여러 문서를 병렬로 처리할 수 있어요.
특히 긴 문서나 복잡한 형식의 문서도 처리할 수 있도록 타임아웃과 에러 핸들링을 잘 해뒀어요.
Chunking 모듈
문서를 의미 있는 단위로 나누는 모듈이에요. 우리의 청킹 전략은:
- 헤더 기준 분할: Markdown 헤더(
#,##등)를 기준으로 섹션을 나눔 - 문단 기준 세분화: 섹션이 너무 길면 문단 단위로 다시 나눔
- 오버랩 유지: 청크 간 200자 오버랩을 두어 문맥 유지
이렇게 하면 "이 섹션은 버그 해결 방법에 대한 내용이구나" 같은 의미 단위로 검색이 가능해져요.
Embedding 모듈
텍스트 청크를 벡터로 변환하는 모듈입니다. Gemini의 text-embedding-004 모델을 사용해서 768차원 벡터로 변환해요.
배치 단위로 처리해서 효율성을 높였고, 진행 상황도 실시간으로 추적할 수 있어요.
RAG 모듈
가장 핵심이 되는 모듈입니다! 사용자의 질문을 받아서 관련 문서를 찾고 답변을 생성합니다.
사용자 질문
│
├─→ [Query Understanding]
│ │ Gemini로 메타데이터 필터 추출
│ └─→ { trackerName: "버그", ... }
│
├─→ [Embedding Service]
│ │ 질문을 벡터로 변환
│ └─→ [768차원 벡터]
│
├─→ [Vector DB 검색]
│ │ 코사인 유사도 계산
│ │ 메타데이터 필터 적용
│ └─→ Top-K 청크 반환
│
└─→ [Gemini Chat]
│ 질문 + 컨텍스트 청크
└─→ 최종 답변 생성
4. 핵심 기능 상세
1. 벡터 검색
PostgreSQL의 pgvector 확장을 사용해서 코사인 유사도 기반으로 검색해요. 질문을 임베딩한 벡터와 가장 유사한 Top-K 개의 청크를 찾아옵니다.
최대 50개를 제한둿어요. gemini가 수용할 수 있는 최대 컨텍스트가 다른 모델보다 높아서 개수를 더 늘려도 괜찮을 것 같습니다.
SELECT *, 1 - (embedding <=> $1::vector) AS similarity
FROM document_chunks
WHERE embedding IS NOT NULL
ORDER BY embedding <=> $1::vector
LIMIT $2
2. 자연어 필터 추출
사용자가 "최근 3개월 내 버그 관련 문서"라고 질문하면, 단순히 키워드만 찾는 게 아니라 의미를 이해해서 필터를 추출해요.
Gemini를 활용해서 질문에서 다음 같은 메타데이터 필터를 자동으로 추출합니다:
- 트래커 이름 (버그, 기능, 작업 등)
- 상태 (신규, 진행중, 완료 등)
- 우선순위
- 작성자
- 프로젝트
- 날짜 범위 (생성일, 수정일, 마감일)
- 완료율
- 마감일 지남 여부
예를 들어 "홍길동이 작성한 완료된 작업"이라는 질문에서:
{
"authorName": "홍길동",
"statusName": "완료",
"trackerName": "작업"
}
이런 필터를 자동으로 추출해서 벡터 검색 결과에 적용해요. 그래서 더 정확한 결과를 얻을 수 있습니다
3. 컨텍스트 기반 답변 생성
관련 청크들을 찾았으면, 이걸 컨텍스트로 삼아서 Gemini에게 답변을 생성하게 합니다.
프롬프트는 이렇게 작성했습니다:
당신은 Redmine 이슈와 저널 컨텍스트를 기반으로 질문에 답변하는 도우미입니다.
제공된 컨텍스트를 최대한 활용하여 질문에 답변하세요.
컨텍스트에 직접적인 답변이 없더라도, 관련된 정보가 있다면 그것을 바탕으로 유용한 답변을 제공하세요.
컨텍스트가 질문과 전혀 관련이 없거나 완전히 비어있는 경우에만 "정보가 충분하지 않습니다"라고 답변하세요.
항상 한국어로 답변하세요.
답변은 마크다운 형식으로 작성하세요. 줄 바꿈, 헤딩, 리스트, 코드 블록, 링크, 강조 등의 마크다운 문법을 적절히 사용하여 매우 높은 가독성을 가지는 답변을 제공하세요.
컨텍스트에 직접적인 답이 없어도 관련 정보를 바탕으로 유용한 답변을 제공하도록 설계했지만, 아무래도 개선이 필요할 것 같습니다
5. 데이터 모델
주요 엔티티들을 간단히 소개할게요:
ProcessedIssue
Redmine에서 가져온 이슈 정보를 저장해요. 주요 필드:
redmineIssueId: Redmine의 이슈 IDdescription: Markdown으로 변환된 설명descriptionRaw: 원본 Textile 형식issueMetadata: JSONB로 저장된 이슈 메타데이터 (트래커, 상태, 우선순위 등)status: 동기화 상태
DocumentChunk
문서를 나눈 청크 정보를 저장해요:
sourceType: 출처 타입 (ISSUE_DESCRIPTION 또는 JOURNAL_NOTES)sourceId: 원본 이슈/저널 IDchunkIndex: 청크 순서content: 청크 텍스트metadata: 헤더 정보 등 메타데이터embedding: pgvector 타입의 벡터 (768차원)
ProcessedJournal
Redmine 저널(댓글) 정보를 저장해요. 이슈와 마찬가지로 notes와 notesRaw 필드가 있어요.
마무리
이렇게 해서 사내 문서 RAG 챗봇 프로토타입을 완성했어요! 아직 프로토타입 단계지만, 실제로 팀원과 같이 사용해보니 꽤 유용하더라고요. 생각지도 못한 이슈에서 해결한 문제도 있어요.
앞으로 개선할 점들:
- 더 정교한 청킹 전략 (의미 단위로 더 잘 나누기, 최소/최대 길이 제한)
- 멀티 모달 검색 (코드 블록, 이미지 등)
- 대화 컨텍스트 유지 (이전 대화 기억)
- 검색 결과 품질 개선 (리랭킹 등)
- 프롬프트 개선
혹시 비슷한 프로젝트를 진행하시는 분들께 도움이 되길 바랩니다