RAG 기반 AI 서비스 설계, 구현하기(RAG 에이전트 개발 실무 과정) 교육을 받고

회사의 그룹웨어 게시판에서 외부강의 안내 게시글이 올라왔길래 읽어보니, 생성형 AI 리터러시, Power BI 데이터 시각화, RAG Agent, 업무 자동화 총 4개였다.
이런 건 참지 않지.
바로 관심 있었던 RAG Agent 외부 교육을 신청했다. 팀장님에게 허락을 받고 스무스하게 신청 완료가 되었다.
혼자서 사내 문서들로 RAG를 만들었지만 생각보다 검색 품질이 좋지 못해 개선하고 싶었고, RAG Agent는 모르는 분야라서 호기심에 신청한 것도 있다. 그리고 팀의 프로젝트에 어떻게 반영할 수 있을지에 대해서도 고민이 있었다. 뭔가 올해에는 우리 팀에 AI가 들어가는 APT 솔루션이 될 것 같은 느낌이다.
입사 초기, 한 1년 미만일 때 몇 번 의문이 들었다. 블로그의 통계를 보여주는 Google Analytics라던가 Sentry 같은 로깅 툴이라던가 프로그램의 에러 리포팅 같은 뭔가 데이터를 수집해서 APT 기능이 아닌 관리자나 사용자에게 정보를 보여주고 개선 및 판단을 할 수 있는 디버깅 기능 같은 게 부족하다고 느껴졌다.
아무래도 B2B 회사니까 제품을 고객사 사내에 설치하고 다시 로그를 팀으로 가져오려면 엔지니어가 직접 고객사에 다녀와야 하니 번거로워 이런 기능이 필요 없다고 판단된 것 같다.
그래서 이와 비슷하게 APT의 데이터를 수집하고 가공해서 사용자에게 자연어로 데이터를 질의하는 식의 편의성을 올려주는 기능이 있으면 좋을 것 같다는 생각이 들어 이 교육을 신청했다.
26.01.22-26.01.23 총 2일 14시간짜리 교육이었다.

교육 커리큘럼은 위와 같았고 주로 강사님이 미리 만들어진 코드를 Google의 Colab에서 실행하면서 로그를 확인하는 방식으로 강의가 진행되었다.
이론과 실습의 비율은 약 1:3 정도였고 대부분의 시간은 실습에 투자되었다.
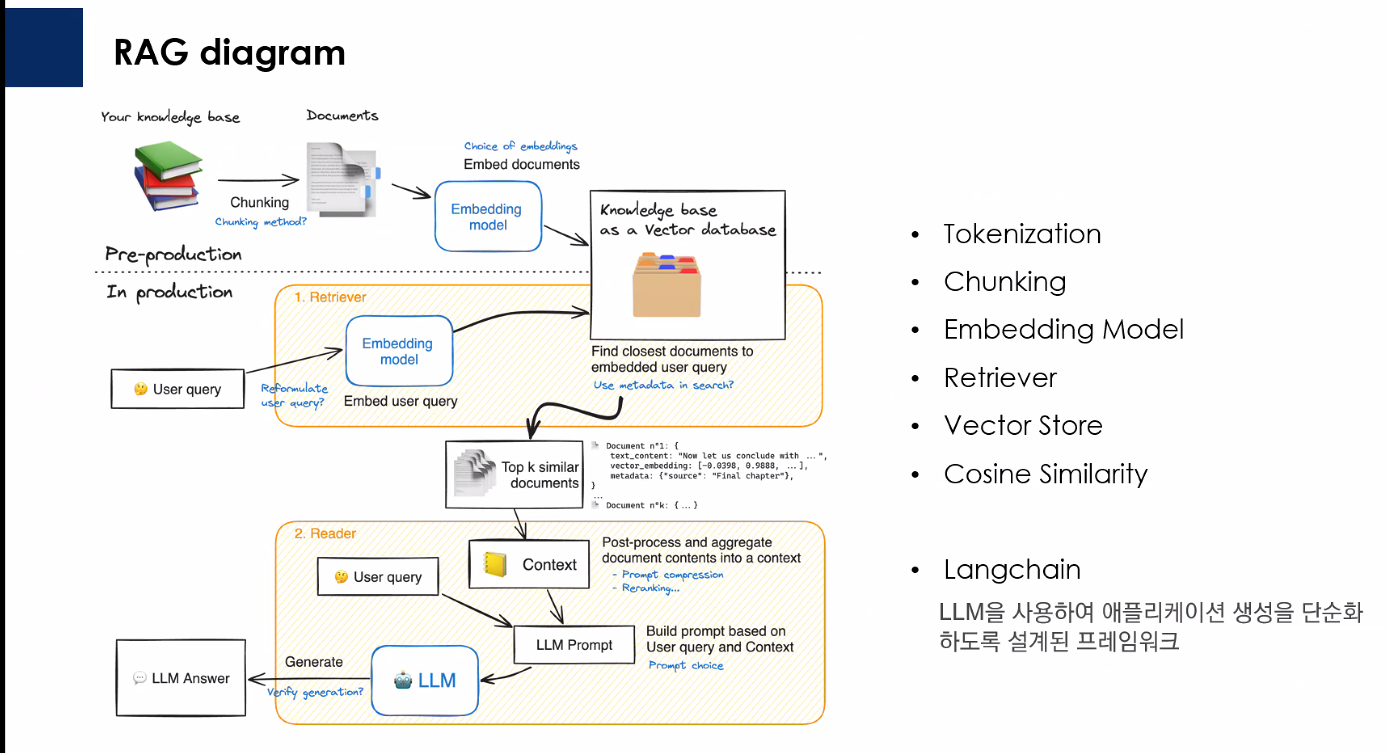
강사님이 처음에 RAG의 흐름이라고 보여주신 그림이다. 전반적인 강의에서 이 그림이 사용되었다.
이전에 사내 문서 RAG를 만들어봐서 이 전통적인 RAG의 흐름은 바로 이해가 됐다.
데이터는 전처리 → 청킹 → 임베딩 → Vector DB 저장의 과정을 거치고, 사용자 질의 → 질의 임베딩 → Vector DB에서 유사도 기반 검색(Top-K) → LLM에게 시스템 프롬프트와 함께 전달 → 응답의 흐름을 가진다.
이 전통적인 RAG의 단점은 명확하다.
데이터와 사용자 질의 두 흐름에서 한 단계라도 품질이 떨어진다면 전체 품질이 떨어지는 단점이 있다. 그리고 어디서 문제가 생겼는지 파악하기도 어렵다.
사내 문서 RAG의 검색 품질이 떨어졌을 때 어디를 고쳐야 할지 감이 잘 안 왔었다. 가장 쉬운 Top-K 개수부터 조절하니 조금 더 좋아지긴 했는데 여전히 문제는 많다.
아무래도 사내 문서는 다양한 사람이 적기 때문에 품질이 왔다갔다 요동친다. 어떤 문서는 이해하기 쉽고 자세하게 적혀있지만, 어떤 문서는 시간 상의 압박으로 문제, 원인, 해결 같이 간단하게 작성된 경우도 많다. 이 데이터 기반으로 검색하기 때문에 실제 개발자나 관리자가 원하는 답을 얻기 어려웠다.
또 최신성 문제... 위와 같은 이유로 개발자는 시간 압박에 쫓긴다... 그러다 보면 문서 최신화는 점점 미뤄지기 때문에 RAG로 검색을 해도 최신 기능이 아닌 이전 기능의 답변이 와서 부정확한 정보를 전달하는 문제도 있다.
사실 이런 문제는 현실적으로 해결할 수 없는 문제가 아닐까 싶다.
그래도 RAG Agent라면 어느 정도 해결할 수 있지 않을까라며 강의를 계속 들었다.
RAG의 핵심 포인트들
강의를 들으면서 RAG의 품질을 좌우하는 핵심 포인트들을 정리해봤다.
청킹(Chunking)의 중요성
청킹은 정말 중요한데, 너무 작게 자르면 문맥이 끊기고, 너무 크게 자르면 검색이 뭉개져서 정확한 부분을 못 찾게 된다. 강의에서는 헤딩 기반 + 길이 기반 + 오버랩을 혼합하는 방식을 추천했다.
오버랩은 슬라이딩 윈도우처럼 의도적으로 중복된 데이터로 청킹하는 건데, 이렇게 하면 문맥이 끊기는 문제를 어느 정도 완화할 수 있다고 한다. 그리고 recursive 방식도 여기서 다시 만나서 재미있었는데, 문서의 헤딩 구조(h1, h2, h3)를 기준으로 재귀적으로 청킹하는 방식이었다.
사내 문서 RAG를 만들 때도 헤딩을 기준으로 청킹했는데, 여전히 품질이 아쉬웠던 이유가 이 부분에 있었을 수도 있겠다. 오버랩을 제대로 적용하지 않았거나, 청킹 크기를 조절하지 않아서 그랬을 수도 있고.
메타데이터의 활용
메타데이터를 잘 활용하면 검색 품질을 크게 개선할 수 있다고 했다. 문서의 source, title, section, created_at/updated_at, project, permission 같은 정보를 함께 저장해두면 필터링이나 그룹핑, 출처 표기가 훨씬 쉬워진다.
특히 최신성 문제를 해결하려면 updated_at 같은 메타데이터로 최신 문서를 우선 검색하도록 하는 게 중요하다고 강조했다. 이건 정말 실무에서 유용할 것 같다.
검색 전략의 다양화
단순히 Top-K만으로는 부족할 수 있어서, Hybrid 검색(BM25 + Vector), MMR(다양성 보장), Rerank(교차 인코더) 같은 기법들을 추가로 고려해볼 수 있다고 했다.
사내 문서 RAG에서 특정 문서로만 검색 결과가 쏠리는 문제가 있었는데, MMR이나 Rerank를 적용하면 이런 편향 문제를 어느 정도 해결할 수 있을 것 같다.
프롬프트의 가드레일
프롬프트에 "근거 안에서만 답해라", "근거가 없으면 모른다고 해라", "출처를 함께 내라" 같은 가드레일을 넣으면 환각을 크게 줄일 수 있다고 했다. 이건 간단하지만 정말 중요한 포인트인 것 같다.
RAG Agent란?
이제 본격적으로 RAG Agent에 대해 배웠다. RAG Agent는 기존 RAG의 "한 번 검색해서 한 번 답변" 방식이 아니라, LLM이 도구(tool)를 사용해서 목표를 달성하도록 만든 형태다.
RAG와 RAG Agent의 차이
- RAG: "검색 → 답변" 단발성 파이프라인
- RAG Agent: "검색 → 검증/추가검색/정리 → 답변" 반복적 의사결정 루프
RAG Agent는 필요하면 여러 번 검색할 수 있고, 근거가 부족하면 쿼리를 재작성해서 재검색하거나, 사용자에게 추가 질문을 할 수도 있다.
RAG Agent의 동작 방식
RAG Agent는 기본적으로 이런 루프를 돈다:
- Plan: 사용자의 질문을 "검색 가능한 쿼리"로 쪼갬 (필요하면 하위 질문 2~3개로 분해)
- Retrieve: 각 쿼리로 문서를 가져옴 (필터/하이브리드/MMR 등 적용 가능)
- Verify: 근거가 충분한지, 서로 일관적인지, 출처가 신뢰 가능한지 점검
- Iterate: 부족하면 쿼리 재작성/추가검색/추가질문 수행
- Answer: 최종 답변 + 출처 + "근거 부족" 처리
이런 반복적인 의사결정 루프를 통해 기존 RAG의 한계를 극복할 수 있다는 게 핵심이었다.
왜 Agent가 필요한가?
강의에서 RAG만으로 부족한 케이스들을 설명해줬다:
- 질문이 애매하거나("이거 어떻게 해?"), 요구사항이 복합적일 때("장애 대응 절차 + 담당자 + 링크")
- 검색 결과가 한 문서로만 쏠리거나(편향), 서로 모순되는 근거가 섞일 때(버전 차이)
- 답변 전에 해야 할 일이 있을 때 (최신 문서 우선, 권한 필터, 여러 소스 종합 등)
사내 문서 RAG에서 겪었던 문제들이 정확히 여기에 해당했다. 특히 검색 결과가 특정 문서로만 쏠리는 편향 문제는 RAG Agent로 해결할 수 있을 것 같다.
실무에서 꼭 넣어야 하는 가드레일
RAG Agent를 실무에 적용할 때는 이런 가드레일들이 필수라고 했다:
- 중단 조건: 최대 반복 횟수, 최대 검색 호출 수, 최대 컨텍스트 토큰(예산) 설정
- 권한 필터: retrieval 단계에서 ABAC/RBAC 필터링 ("답변 시 필터"는 늦음)
- 출처 정책: 답변에 문서 id/섹션/링크를 항상 포함
- 불확실성 처리: 근거 부족 시 "모름/추가 정보 요청"을 강제
- 관측성(로그): 어떤 쿼리로 무엇을 가져왔는지 기록
비용과 안전, 신뢰를 위해서는 이런 가드레일들이 정말 중요하다는 걸 배웠다.
파인튜닝과 LoRA
강의 중간에 파인튜닝과 LoRA에 대해서도 배웠다. 이건 RAG와는 다른 접근 방식이지만, 함께 사용하면 더 강력해질 수 있다고 했다.
파인튜닝 vs RAG
파인튜닝은 모델 자체의 행동을 바꾸는 방법이고, RAG는 외부 지식을 검색해서 사용하는 방법이다.
- RAG가 유리한 경우: 사내 문서가 자주 바뀜, "근거/출처"가 중요, 답변이 틀리면 리스크가 큼
- 파인튜닝/LoRA가 유리한 경우: 답변의 형식/톤/정책 준수가 핵심, 업무 분류/라우팅/추출 같은 반복 패턴
실무에서는 RAG로 최신 지식/근거를 공급하고, LoRA로 출력 포맷/정책/도구사용(에이전트 동작)을 안정화하는 조합이 가장 흔하다고 했다.
LoRA는 전체 모델을 다 학습하지 않고, 작은 어댑터만 학습하는 방식이라 비용과 메모리를 크게 절감할 수 있다는 게 인상적이었다.
실습과 결과물
강의는 대부분 실습 위주로 진행되었다. Google Colab에서 미리 준비된 코드를 실행하면서 로그를 확인하는 방식이었는데, 이론만 듣는 것보다 훨씬 이해가 잘 됐다.
실습에서는 로컬 파일을 벡터 인덱스로 만들고, 검색하고, LLM에게 전달해서 답변을 생성하는 전체 파이프라인을 직접 구현해봤다. 간단한 예시였지만 RAG의 전체 흐름을 한눈에 볼 수 있어서 좋았다.
강사님이 만든 결과물도 공유해주셨는데, 이미지 분석을 하는 RAG Agent였다. Gradio로 웹 UI를 만들고 Vercel에 배포한 형태였고, 실제로 동작하는 걸 보니 신기했다.
교육을 마치며
2일 동안의 교육을 받으면서 RAG와 RAG Agent에 대해 많이 배웠다. 특히 사내 문서 RAG의 품질 문제를 어떻게 개선할 수 있을지에 대한 힌트를 많이 얻었다.
- 청킹 전략 개선 (오버랩, recursive 방식)
- 메타데이터 활용 (최신성 필터링)
- 검색 전략 다양화 (Hybrid, MMR, Rerank)
- RAG Agent로 반복적 의사결정 루프 구현
이런 것들을 적용하면 사내 문서 RAG의 품질을 크게 개선할 수 있을 것 같다. 물론 완벽하게 해결되지는 않겠지만, 적어도 사용 가능한 수준까지는 올릴 수 있을 것 같다.
그리고 RAG Agent는 단순히 검색 품질을 개선하는 것뿐만 아니라, 사용자에게 더 자연스럽고 유용한 대화형 인터페이스를 제공할 수 있다는 점에서 매력적이었다. 팀의 프로젝트에 어떻게 반영할 수 있을지 고민해봐야겠다.
결과